

Hyper. Parallel. Computer.
A Technical Exploration of the ao computer

I'm Vedant! I'm a software developer who loves to create awesome web3 and blockchain projects. When I'm not coding, you can find me writing technical articles or exploring new technologies. I'm always up for a chat about the latest tech trends, so feel free to drop me a message!
What is ao?
The ao computer, short for "actor-oriented," is a computing environment built on the foundation of the Arweave network. It emerges not from a single physical machine, but rather from a network of nodes adhering to a specific data protocol.
Despite being distributed across various nodes, the ao computer presents itself as a single, unified computing environment. This "Single System Image" (SSI) simplifies development by providing developers with a consistent experience regardless of the underlying network infrastructure.
Before getting into how ao functions, let us go over some concepts on which ao is built.
Actor model
The actor model is a fundamental concept powering ao's parallel processing capabilities. It defines a set of rules for how independent units called actors interact and exchange information within a concurrent computing environment.
What are Actors?
An actor acts as the fundamental unit of computation within the actor model. Just like objects in object-oriented programming respond to method calls, actors handle incoming messages by executing the defined logic associated with that message.
Each actor has an address. It can be a direct physical address, such as MAC address, a memory address, or simply a process identification (PID). Multiple actors can have the same address, and a single actor can have multiple addresses. There is a many-to-many relationship here.
Address is not a unique identifier for the actor. Actors have no identity, only addresses. So, when we see our conceptual Actor Model, we can only see and use addresses. Even if we have a single address, we can't know if we have one or many actors because it might be a proxy for a set of actors.
What can Actors do?
Actors can receive and send messages from/to other actors within the system. These messages contains data structures that contain instructions for a task. This can be used to delegate tasks or divide computation work.
Each actor can hold its own private data, often referred to as its state. This state represents the internal information specific to that actor and is not directly accessible to other actors.
Messaging
When you send a message to an actor, the message doesn’t go directly to the actor, but goes to the actor’s mailbox until the actor gets time to process it.
Mailbox is an actor (remember: everything is an actor), which represents messages’ destination point. Mailboxes are not required by an Actor, because if an Actor was required to have a mailbox then, the mailbox would be an Actor that is required to have its own mailbox and we end up with an infinite recursion.
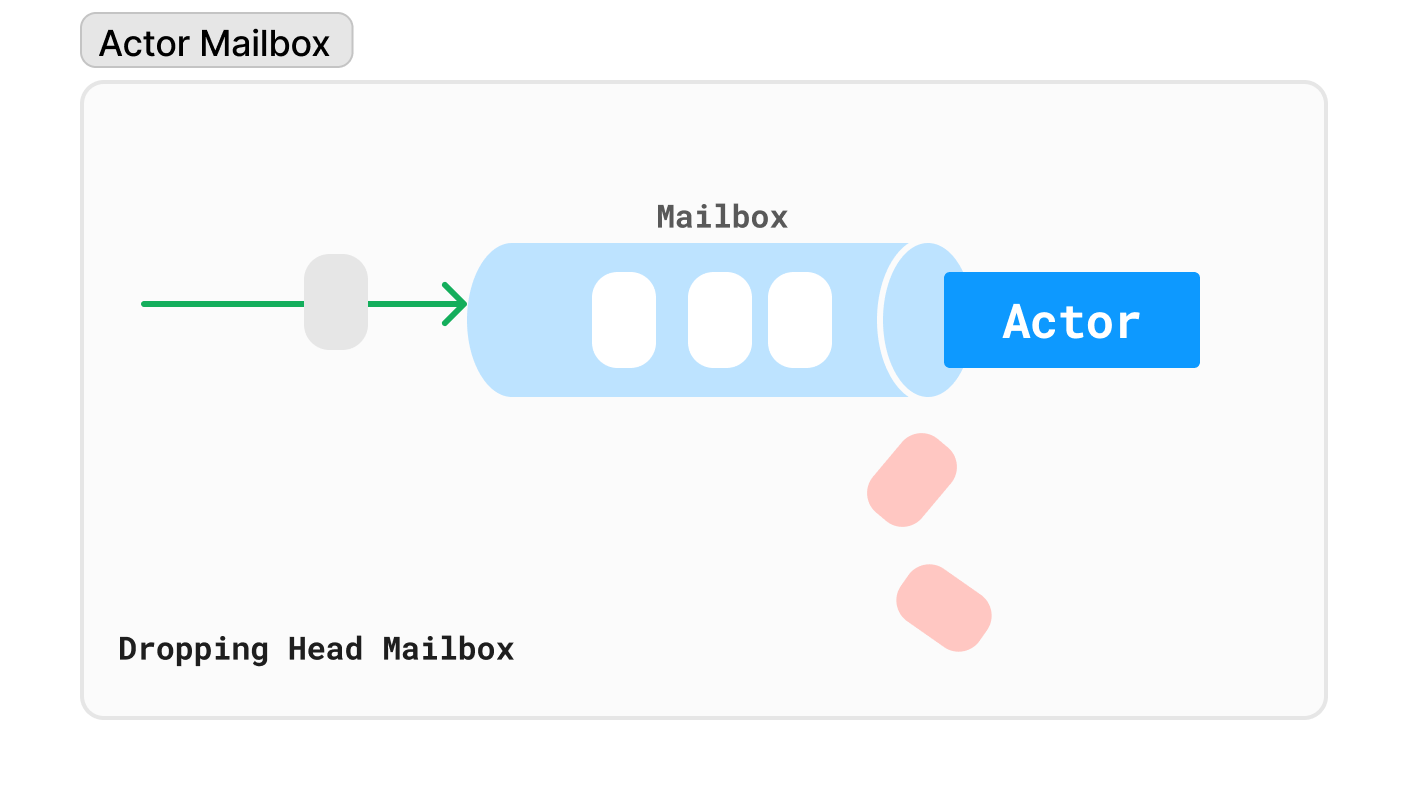
Upon receiving a message, an actor has three primary options:
Create new actors: An actor can dynamically create finite number of new actors to handle specific tasks or subdivide the received work. This allows for hierarchical structures within the system, enabling actors to delegate tasks to other actors.
Send messages to other actors: Actors can send messages to other actors to initiate further processing or request information. This facilitates collaboration and data exchange between actors.
Update internal state: While actors cannot directly modify another actor's state, they can update their internal state based on the received message for the next message. This internal state captures the actor's current context and influences its behavior for future messages. However, unlike traditional programming where state changes happen "in-place," the actor model employs a concept called immutable state. This means the actor creates a new copy of its state with the updated information instead of modifying the existing one.
An actor processes incoming messages from his mailbox sequentially, one at a time, although real implementations always optimize or pipeline message processing in some manner.
Futures
The actor model allows actors to send messages to themselves, enabling a form of self-recursion. However, to prevent deadlocks (situations where actors wait for each other indefinitely), the concept of futures is introduced.
A future is a placeholder for a function result (a success or failure) that will be available at some point in the future. It’s effectively an asynchronous result handle. It gives you a way to point at a result that will eventually become available.
Actors can freely exchange futures with other actors, including sending them to themselves. This allows them to initiate tasks and continue processing other messages while waiting for the future's value to become available. This asynchronous communication helps avoid deadlocks and improves overall system efficiency.
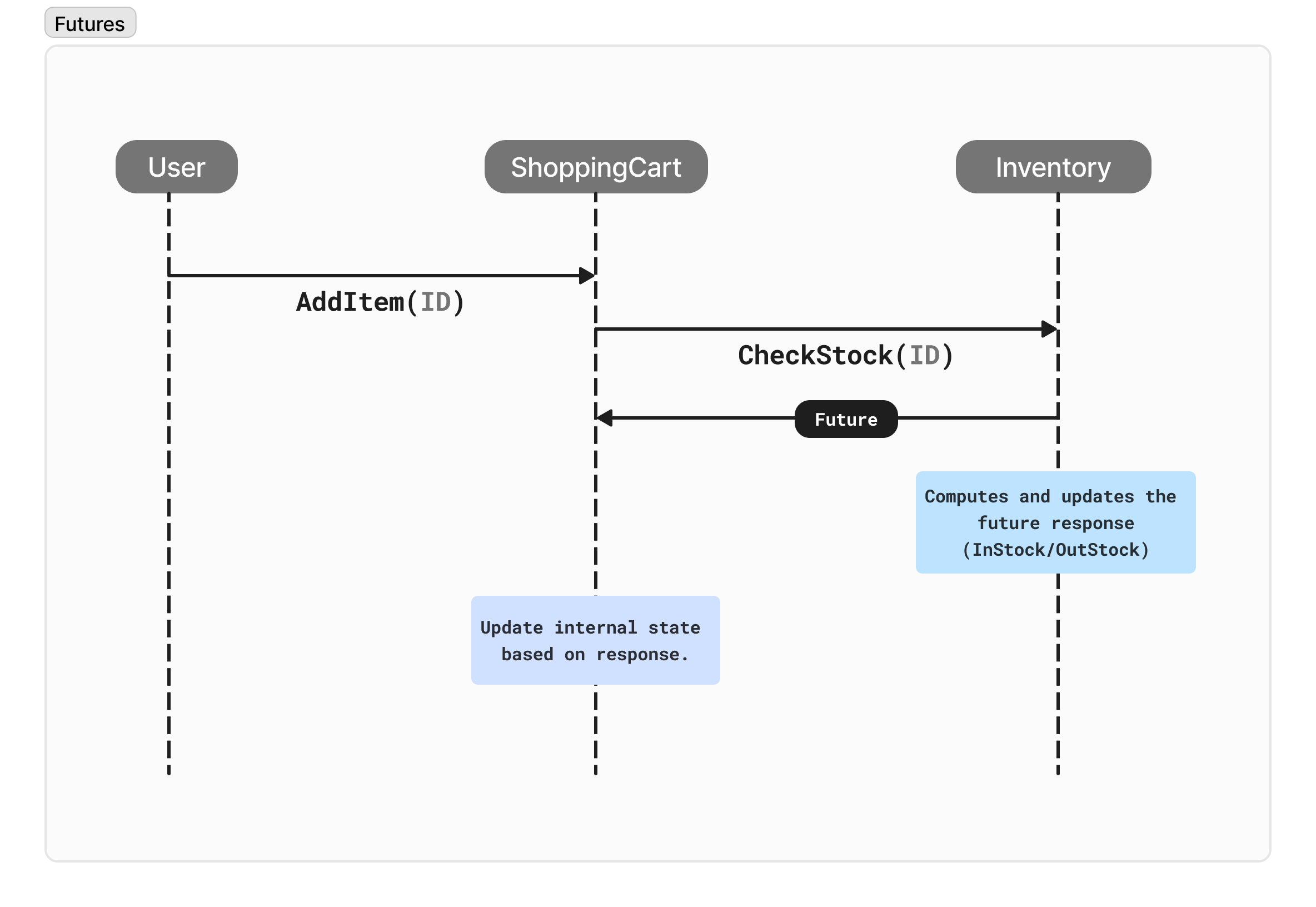
Let's understand futures with help of an example
Take an online store where users can add items to their shopping carts and purchase them. We can implement this using the actor model with futures to avoid deadlocks:
User: Represents the customer browsing the store and adding items.
ShoppingCart: Manages items added to the cart and calculates totals.
Inventory: Tracks available items and handles stock updates.
Interaction Flow:
User: Sends a "AddItem" message to ShoppingCart with the desired item ID.
ShoppingCart:
Updates its internal list with the new item.
Sends a "CheckStock" message to Inventory, containing the item details, and receives a future representing the stock availability.
Inventory:
Checks availability and prepares a response message ("InStock" or "Out of Stock").
Sends this response message back to the ShoppingCart as a reply.
ShoppingCart (when receiving the response from Inventory):
- Unpacks the future's value (stock availability) and updates its internal state.
Single System Image(SSI)
The concept of a Single System Image (SSI) is central to understanding how the ao computer operates. Despite being distributed across a network of individual nodes, ao presents itself as a single, unified computing environment. This means that developers and users can interact with the entire network as if it were one large computer.
Let's understand this with an analogy, Imagine a large office building with multiple floors, each containing individual departments or teams. While physically separate, these departments collaborate and share resources to achieve a common goal. Similarly, in the context of ao:
Individual floors represent the various nodes within the distributed network.
Each department on a floor represents an independent process running on a specific node.
Communication channels like hallways and elevators connect the departments, enabling them to exchange information and collaborate.
The ao Architecture
The ao computer is built upon a foundation of key components working together to facilitate parallel processing and communication.
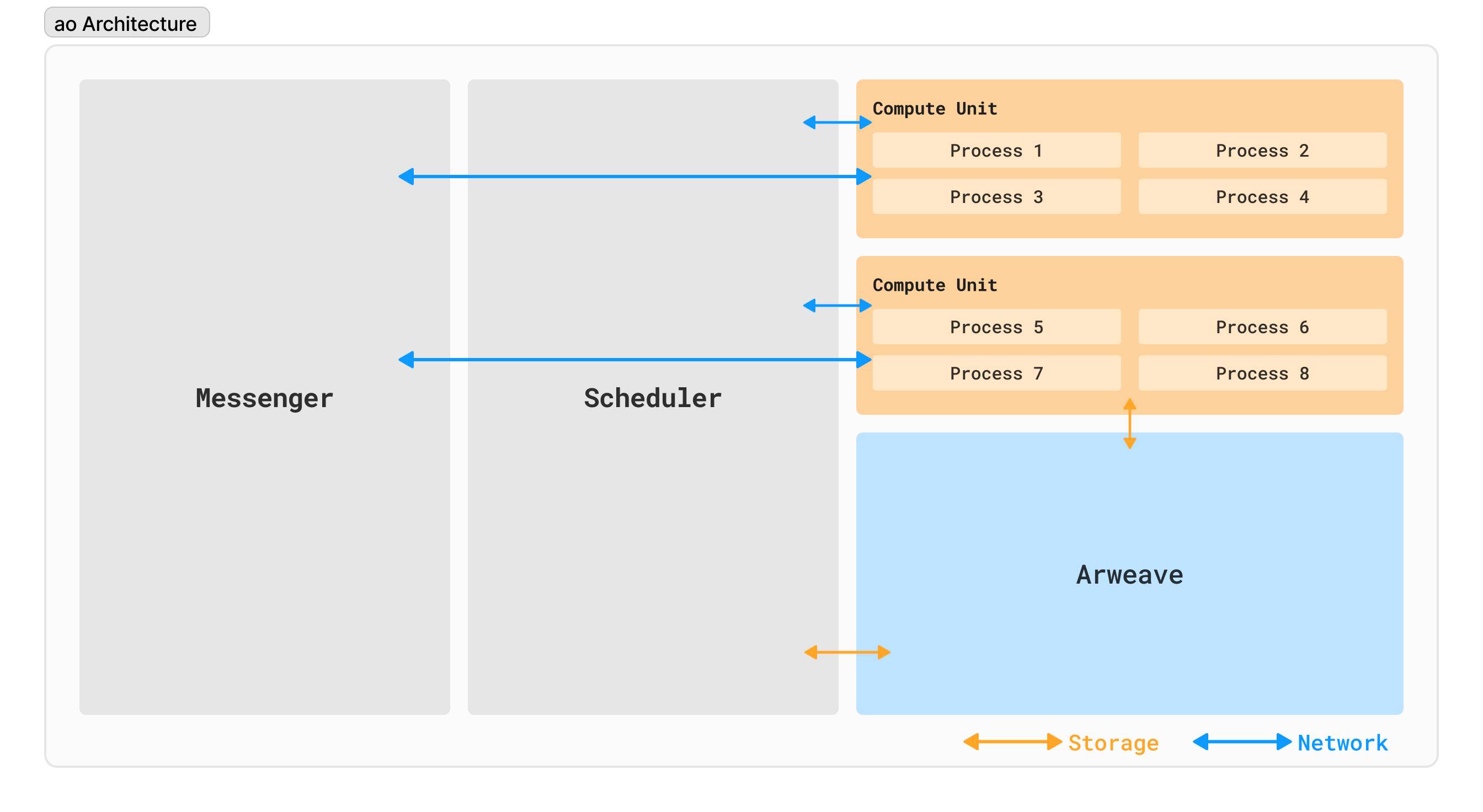
Processes
Processes are the fundamental building blocks of computation within the ao system. Imagine them as independent actors, each responsible for carrying out specific tasks. Here's a breakdown of their key aspects:
Each process is essentially a log of interacting messages stored on the Arweave network. This log captures the history of all messages received and sent by the process, which ensures transparency and auditability.
Additionally, each process has an initialization data item. This data specifies the process's requirements, including:
Virtual Machine (VM): The type of virtual environment needed to run the process's code. (ao doesn't enforce a specific VM, allowing flexibility).
Scheduler: The algorithm used to determine how the process prioritizes and executes tasks.
Memory Requirements: The amount of memory the process needs to function.
Extensions: Any additional functionalities required by the process, like accessing specific virtual resources.
Formal Representation:
For technical readers, here's a formal representation of a process denoted by Pi :
$$P_i = ( Log_i , Init_i , Env_i )$$
Logi : Ordered sequence of messages for process Pi.
Initi : Initialization data specifying the process's environment.
Envi : Computing environment, including VM, scheduler, memory, and extensions.
Decentralized State Management
One crucial aspect of ao's process design is decentralized state management. Unlike traditional systems where processes directly modify their own state, ao adopts a different approach:
The state of a process at a given point in time, denoted by Si , is not explicitly stored within the process itself.
Instead, it is derived by a function
Fdefined by the process's environment (Envi). This function takes the process's message log and environment as inputs and computes the current state.
$$S(P_i) = F( Log_i , Env_i )$$
Message Sending and Outbox:
As processes interact by sending messages, an important concept is the outbox. This holds the new messages generated by a process in response to a received message m. It can be represented by a function:
$$Outbox_m = F(Log_i, Env_i, m)$$
Messages
Every interaction within the ao system is based on messages. These messages act as the primary means of communication and collaboration between processes and users. Here's a breakdown of their key aspects:
Format and Delivery:
Messages in ao are structured according to the ANS-104 standard. This ensures compatibility and standardized data exchange across different entities within the network.
Messages are sent and received by processes through outboxes and messenger units respectively. Scheduler units play a role in routing messages towards their intended recipient processes.
Formal Definition:
We can represent the jth message in process Pi as Mij. This message is represented as an ANS-104 compliant data item, ensuring a structured format for efficient communication.
Delivery Status:
The delivery status of a message Mij., denoted by D(Mij) , can be represented as:
$$D(M_(ij)) = \left\{\begin{matrix} & 1 & If & delivered \\ & 0 & Not & delivered \end{matrix}\right.$$
Delivery Guarantees
ao uses at-most-once delivery semantics. This means that a message is guaranteed to be delivered at most once to the recipient process. However, there are two scenarios where a message might not be delivered:
Messenger Unit Failure: If the messenger unit responsible for forwarding the message fails, the message might not reach the recipient.
Process Not Processing Messages: Even if the message is delivered, the recipient process might not be actively processing messages at that specific moment, leading to potential delays or missed messages.
Reliability Through Arweave
While at-most-once delivery might seem unreliable at first glance, ao mitigates this through its integration with the Arweave network. Arweave provides a persistent storage mechanism for all process message logs. This means that even if a message is not delivered initially, its existence within the process's log on Arweave allows for recomputation later on.
Here's how this works:
If a process Pi is suspected to have missed a message due to any reason, its outbox Outbox(Pi) can be recomputed by applying the process's logic (
F) to its message log (Logi).This recomputation can potentially identify any undelivered messages, and they can be resent to the recipient process for further processing.
Messenger Units (MU)
Messenger Units (MUs)*(pronounced "moo" 🐄) are nodes within the ao network responsible for *delivering and processing messages between processes.
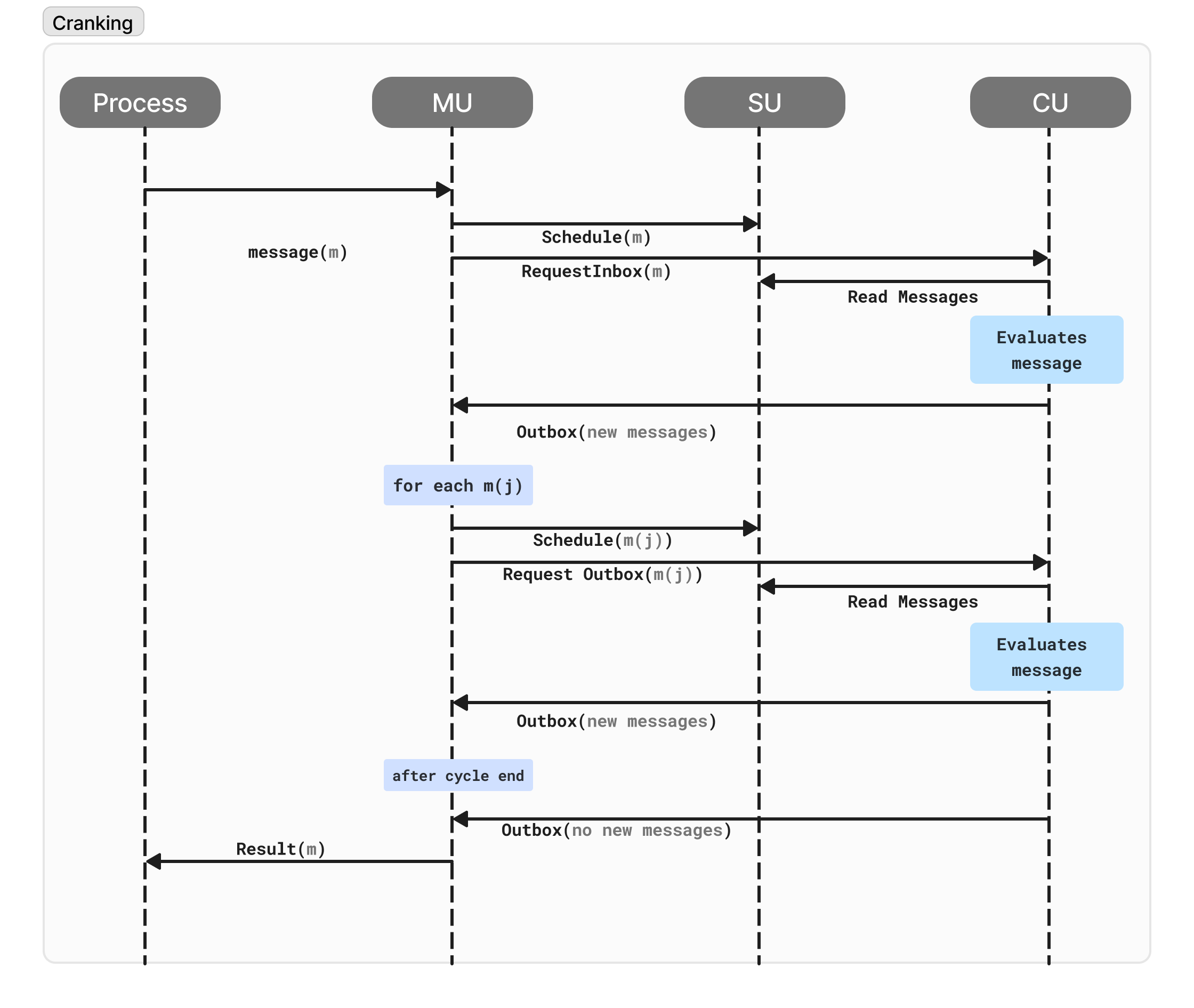
MUs employ a process called cranking to move messages around the network and coordinate their execution. Here's a breakdown of the cranking workflow:
Message Receipt: An MU receives a message (mi) from a user or another process.
Scheduler Involvement: The MU forwards the message (mi) to the appropriate Scheduler Unit (SU) for the target process. This ensures proper scheduling and ordering within the process's message queue.
Compute Unit Interaction:
The MU requests the outbox of a chosen Compute Unit (CU). This outbox might contain new messages generated (actors can send messages to another actors) as a result of processing the current message (mi) by the process.
If the outbox is not empty, the MU:
Takes each new message (mj) from the outbox.
Signs the message to ensure its authenticity and integrity.
Forwards the signed message (mj) back to the appropriate SU, continuing the cycle recursively.
Formal Representation:
The Push(MUm, M) function formally defines the cranking operation, where:
MUm: Represents the messenger unit.
M: Represents a set of messages.
The function recursively iterates through the message set, performing the following actions:
If the message set is empty (
M = ∅), the function returns an empty set (∅).For each message
min the set:The message is sent to the appropriate SU (SUk(σ(MUm, m))).
The
Pushfunction is recursively called on the output (out) generated by the CU upon processing the messagem. This continues the processing chain for any resulting messages.
Additional Features:
Subscriptions: Users and processes can pay MUs to subscribe to specific processes. This allows the MU to automatically crank any messages generated by the subscribed process based on its scheduled cron jobs (more on cron jobs later).
Casting: Processes can choose to send a message as a cast. This instructs the MU to deliver the message to the intended process's SU but not wait for a response. This is useful for one-way communication scenarios.
Scheduler Units (SU)
Scheduler Units (SUs)*(pronounced "soo" 👧) play a important role in the ao system by managing the *ordering and persistence of messages for individual processes.
SUs handle incoming messages (m) for a specific process (Pi) and perform the following tasks:
Assignment
Each message receives a unique nonce (
n), acting as an incremental sequence number within the process. This ensures proper ordering and prevents message duplication.The assignment process is formally represented as:
$$A(m) = (m, n, \sigma (SU_{P_i}, m, n))$$
*
A(m): The assigned message with its nonce.*
m: The original message.*
n: The assigned nonce.*
σ(SU_Pi, m, n): The cryptographic signature of the SU over the message and its nonce, ensuring authenticity and integrity.
Persistance
After signing, the SU persists both the signed message and its assigned slot number onto the Arweave data layer. This ensures the information is permanently stored, verifiable, and accessible to anyone within the network.
Stake Slashing
To incentivize proper behavior and prevent malicious activities, SUs are associated with a stake (S(SUPi)). This stake is subject to being slashed under certain defined conditions:
Failure to Assign or Dropping Messages: If an SU fails to assign a slot number to a message (
m) or intentionally drops the message, its stake will be slashed as a penalty for non-compliance.Persistence Failure: If an SU assigns a slot number but fails to persist the signed message and assignment onto Arweave, creating a gap in the process's message log, its stake will be slashed.
Duplicate Slot Assignment: If an SU assigns the same slot number (
n) to different messages (m1andm2), its stake will be slashed to prevent manipulation of the message order.
Compute Units (CU)
Compute Units (CUs)*(pronounced "koo" 🦘) act as the computational workhorses within the ao network. They play a crucial role in *determining the state of processes based on incoming messages. Here's a breakdown of their key aspects:
Market for Computation
Unlike Scheduler Units (SUs), which are obligated to process messages for accepted processes, CUs operate in a peer-to-peer market for computation.
This means users and messenger units (MUs) can choose any available CU to calculate the state of a process, creating competition among CUs.
CUs compete based on various factors, including price, computational requirements of the process, and other parameters, offering users flexibility and cost-effectiveness in selecting the appropriate CU for their needs.
Processing and Attestation
Once a CU is chosen, it executes the virtual machine (VM) function (
λ) defined for the specific process (Pi). This VM function is responsible for processing the incoming message (Mj) and determining the resulting state of the process.The processing outcome is a tuple containing:
Φi : The updated state of the process Pi.
Outboxj: The set of new outbound messages generated by processing the message Mj.
Attestj: A signed attestation of the entire computation performed by the CU. This attestation serves as a verifiable proof of the process state update and message generation.
$$λ(P_i,m_j) = <Φ_{P_i}, Outbox_j, Attest_j>$$
- CUs can also generate and publish signed state attestations independently. These attestations can potentially be used by other nodes in the network, with the option of paying a UDL (Universal Data Link) fee specified by the CU.
Message Flow
Imagine a user wants to update a profile picture on a social media application built on the ao network. The application process (denoted as Process (Pi) in the diagram) is designed to handle profile updates.
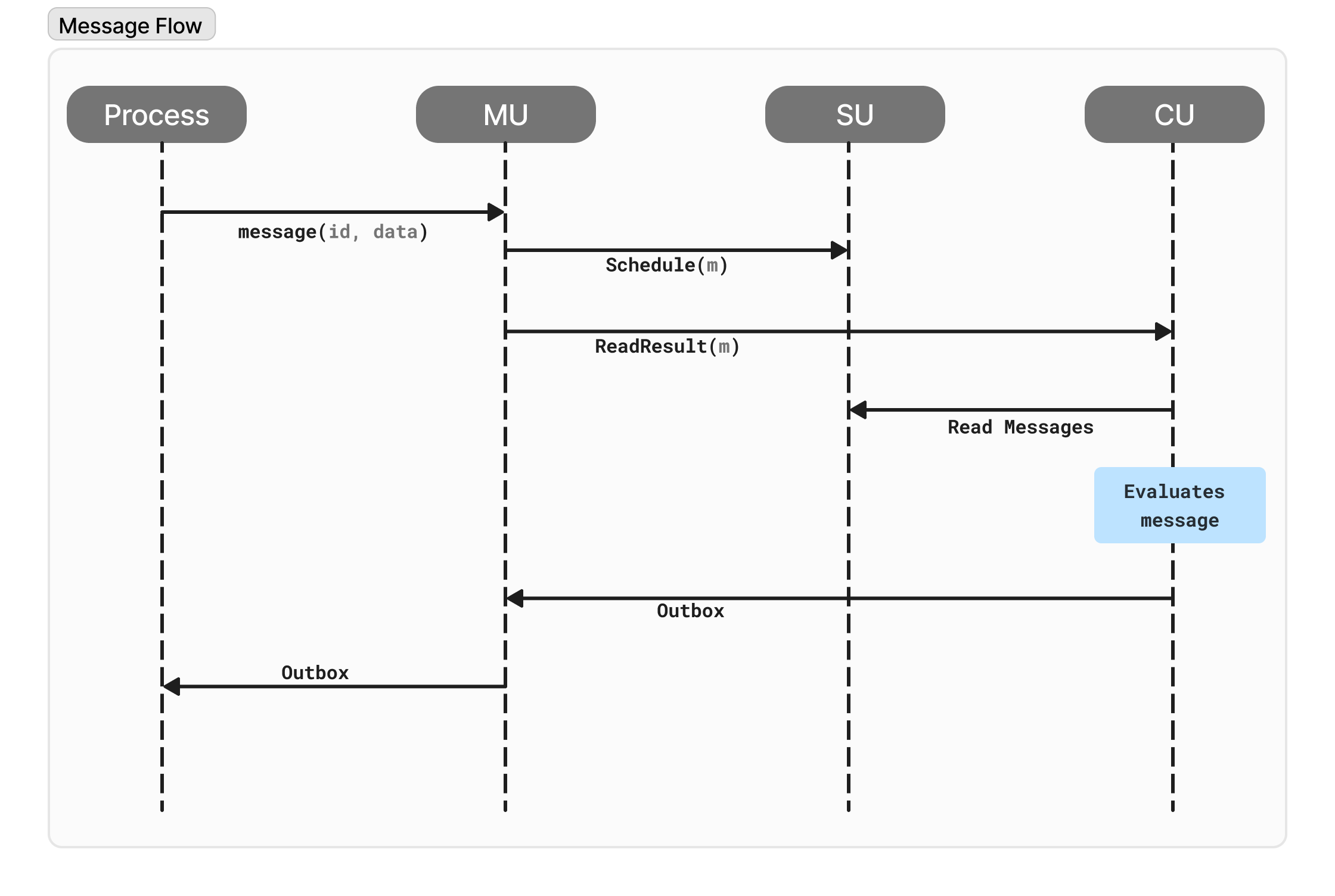
User Creates Message: The user initiates the update by selecting a new profile picture and clicking "Save". The social media application translates this action into a message mi containing the user's ID and the new picture data.
User Sends Message: The application sends the message mi to the messenger unit (MU) designated for interacting with process Pi (the social media profile update process).
MU Sends Message to Scheduler Unit (SU): The MU receives the message mi and forwards it to the appropriate scheduler unit (SU) responsible for process Pi.
SU Assigns Slot and Signs: The SU receives mi and assigns it a unique slot number within the sequence of messages for process Pi. It then cryptographically signs the message mi along with the assigned slot number to ensure tamper-proof delivery and accurate ordering.
SU Persists Message: After signing, the SU stores the signed message (mi) and its assigned slot number permanently on the Arweave data layer. This ensures the message is verifiable and recoverable if needed.
MU Requests Outbox from CU: The MU doesn't directly process the message but interacts with a compute unit (CU) specializing in handling social media profile updates. The MU requests the current outbox of the chosen CU.
CU Processes Message and Generates Outputs: The CU retrieves the message mi from its outbox (which might contain other messages depending on the workload). It then processes mi according to the social media application's logic defined by the process's virtual machine (VM). This processing might involve updating a database, creating a new profile picture record, and generating notifications for followers. The outcome of this processing is a tuple containing:
The updated state of the social media profile process (Φi).
A new outbound message (Outboxj) containing information about the update, potentially sent to other processes or stored for future reference.
A signed attestation (Attestj) of the entire computation performed by the CU, which serves as proof of the update's validity.
CU Returns Results (Recursive Process): The CU sends the processing results (signed attestation Attestj and potentially a new outbound message Outboxj back to the MU. This might trigger a recursive process where the MU handles the new outbound message (Outboxj) by potentially requesting the SU to assign a slot number, persisting it, and then requesting the outbox of another CU responsible for further processing (e.g., notification generation).
User Receives Update Confirmation (Optional): Depending on the application's design, the social media application might receive a confirmation message from the process or the MU indicating that the profile picture update was successful.
Cron Messages
ao also supports cron messages that allows processes to schedule tasks and automatically send messages at defined intervals.
Processes can be configured to generate messages at specific intervals such as seconds, minutes, hours, or even blocks within the network.
These automatically generated messages are then evaluated by a dedicated monitoring process. This monitoring process essentially informs the relevant process that it has a message to evaluate, allowing for real-time processing and communication.
Scheduling
Cron messages are defined using tags during process creation. These tags include:
Cron-Interval: Specifies the interval at which the message should be generated (e.g.,1-Hourfor every hour).Cron-Tag-{Name}: Allows for additional custom tags to further define the message's purpose and behavior.
Evaluation
Similar to scheduled messages, cron messages are evaluated by compute units (CUs) within the ao network. These CUs execute the process's virtual machine (VM) based on the cron message and the process's definition.
Output
Like other messages, cron messages can generate various outputs:
Outboxes: Collections of new messages to be sent to other processes.
Output: Data generated by the process's VM upon evaluation.
Spawns: Requests to create new processes within the network.
Unique Routing
Unlike regular scheduled messages, the outboxes generated by cron messages are not automatically cycled through the standard messenger unit (MU) routine. Instead, they require separate cycling. This ensures that cron messages are processed independently while maintaining control over their routing.
References
Protocol Specification of the ao Computer: Link ↗
Designing Reactive Systems: The Role Of Actors In Distributed Architecture by Hugh McKee: Link ↗
ao cookbook: https://cookbook_ao.arweave.dev
Hewitt, Meijer and Szyperski: The Actor Model (everything you wanted to know...): Link ↗
Erlang Docs: Link ↗



